
Why half your AI SAST findings are wrong (and how to fix them)
AI-powered SAST catches patterns fast, but without context it produces false positives. Here’s why security teams need static analysis, authorization mapping, and dynamic testing together.

I’m a big fan of using AI in security. We’ve been running AI-powered code scanners on every pull request for close to two years now, alongside the usual stack, your CodeQLs, Trivys, TruffleHogs, Dependabots. We even built custom AI agents to hunt for specific vulnerability classes.
So when Claude found a blind SQL injection in Ghost (50,000 GitHub stars, zero critical vulnerabilities in its entire history) in 90 minutes, I wasn’t shocked. I’ve been watching these models get better in real time. And when Claude Mythos leaked a few days ago, described as “far ahead of any other AI model in cyber capabilities,” and cybersecurity stocks dropped 3 to 7%, yeah, I get the excitement. I share it.
But if you actually run this stuff in production, you know it’s not that simple.

When you actually run AI SAST across a real production codebase, day in, day out, you learn to live with a specific reality: the thing works, but it also lies to you. A lot.
You point your AI scanner at a codebase, and it comes back with a list. SQL injection here. SSRF there. Insecure deserialization in this library. Hardcoded credentials in that config. Broken access control on this endpoint. Some of those are real, and give you that w000t moment.
But a lot of them aren’t. I don’t mean edge cases or theoretical stuff. I mean, the scanner is flat-out wrong. It’s flagging things that can’t actually be exploited because it doesn’t have the full picture.
Your AI scanner reads a function, sees a user-supplied parameter going into a database query, and flags it. Possible SQL injection. Severity: High. Makes sense on paper. But what it doesn’t know, what it can’t know just from reading source code, is that three layers up, there’s an API gateway stripping special characters before the request ever reaches this function. Or there’s middleware parameterizing the query. Or that “user-supplied” input is actually coming from an internal service that already validated it.
The scanner sees the code. It doesn’t get the full picture.
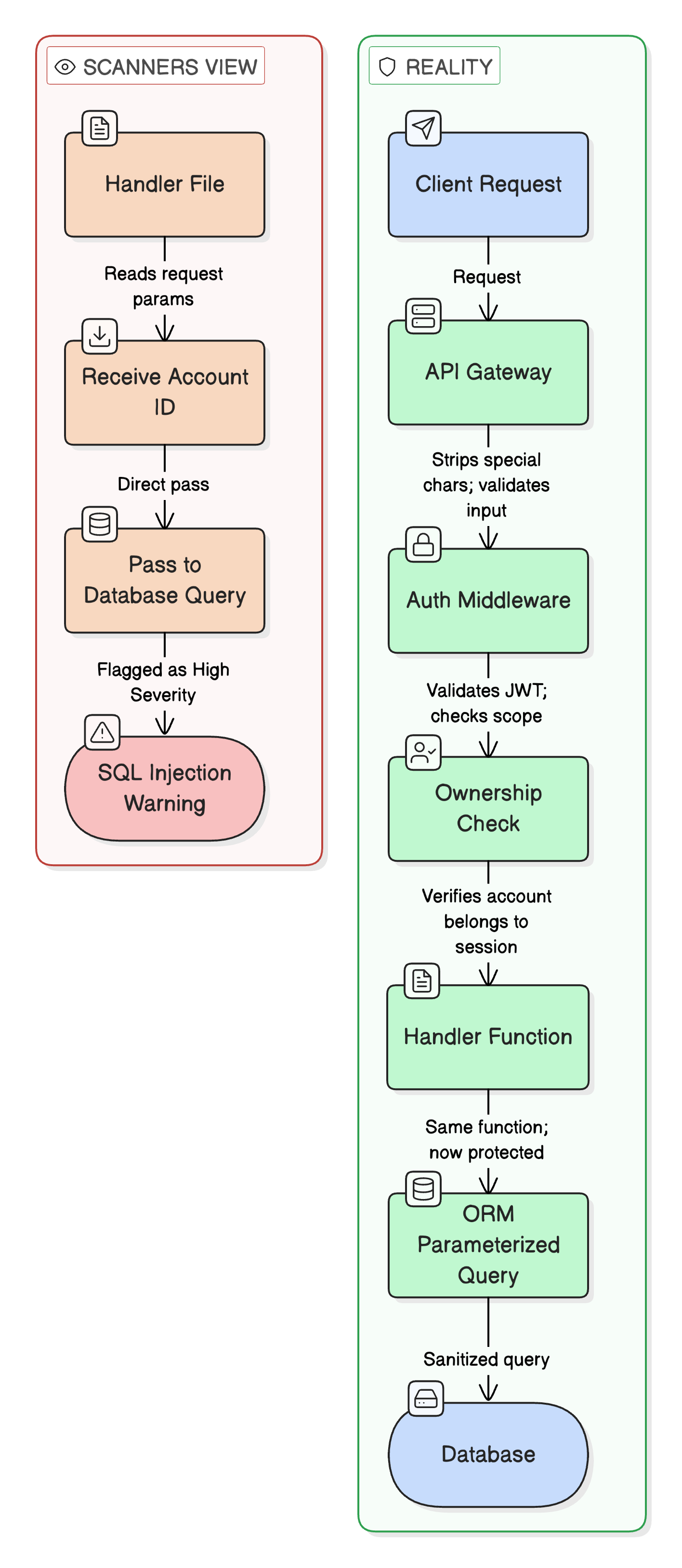
Same thing with access control. The scanner sees an account ID passed as a parameter and forwarded downstream without an ownership check in that file. Flags it Critical. But it has no idea whether the API gateway injects a verified client identity header upstream, or whether the downstream service validates against it. The enforcement might live in a completely different service, maybe even on a different platform. The scanner can’t tell.
So what actually happens? Your AI hands you 200 findings, and your team spends the next two weeks triaging them. Half are real. Half are garbage. And the only way to figure out which is which is to manually check each one against the running system.
Nobody has time for that. So this is what I’ve been building instead.
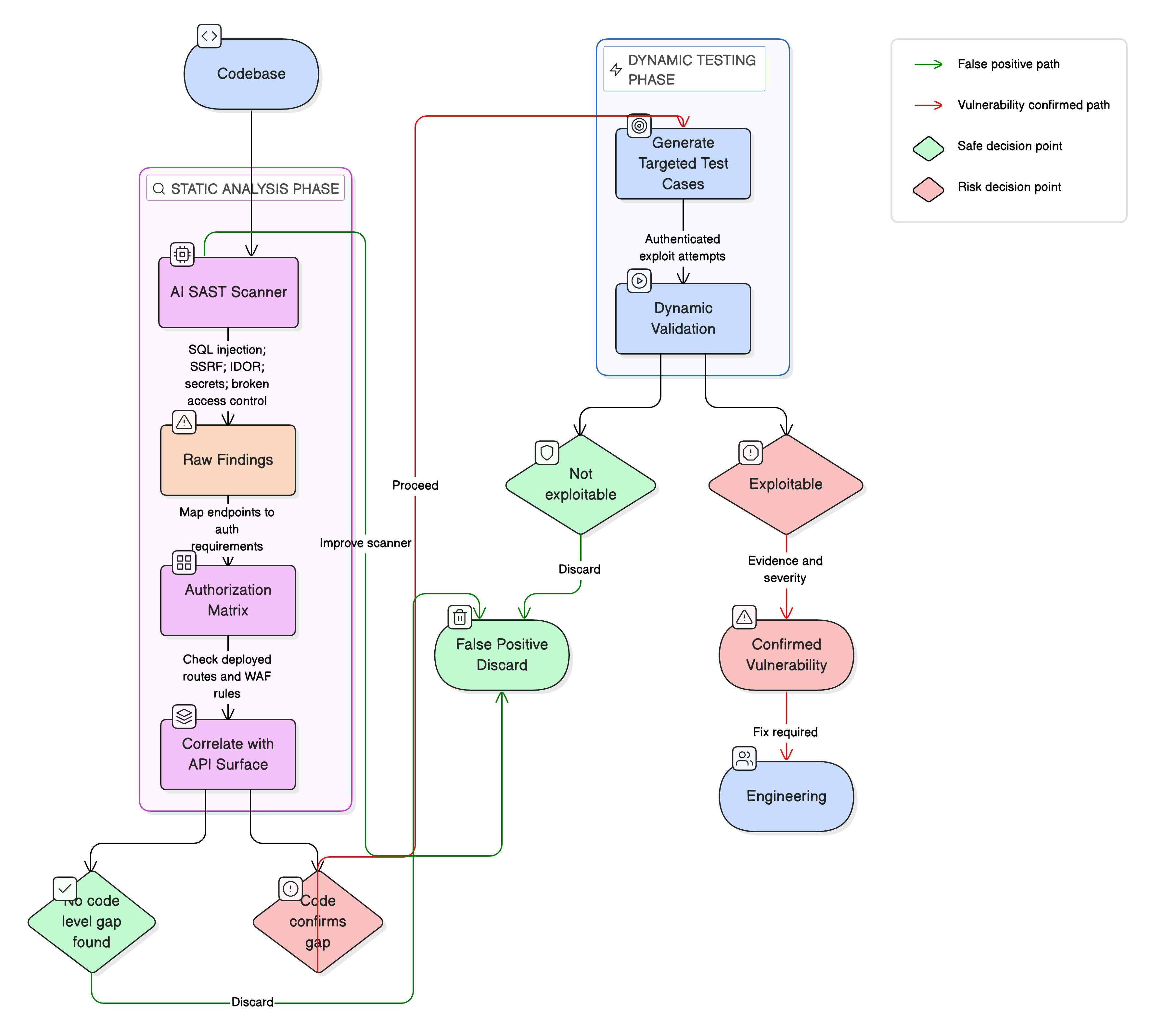
What if you didn’t stop at the SAST results? What if you took those findings and actually tested them?
The philosophy is simple: code first, exploit second.
Instead of running a generic scan and dumping results on someone’s desk, you structure it. You map every endpoint to its full middleware chain, its auth requirements, its authorization checks. Most of this stuff is code, by the way. Your API gateway config, your middleware handlers, your route definitions, they’re all sitting in repos. But nobody points the scanner at all of it together. The gateway config is in one repo, the back-end in another, auth rules in YAML somewhere else, WAF in a Terraform file. Teams scan the application code and call it a day. The full picture never makes it into one scan.
So you build it yourself. I’ve been building what I call an authorization matrix for every endpoint in your API surface.
At its simplest, it’s a structured map that answers four questions for every route:
Who is the caller? (auth mechanism: JWT, session, API key)
Where does identity come from? (header, token claim, request param)
What checks are enforced? (middleware, service-level validation)
Where are those checks implemented? (gateway, app, downstream service)
Most of this data already exists, just scattered:
API gateway configs (routing, auth injection)
Middleware chains in application code
Infrastructure definitions (WAF, proxies, service mesh)
Downstream service validation logic
The matrix stitches all of that into a single view. It shows you every gap at once instead of hunting through endpoints one at a time.
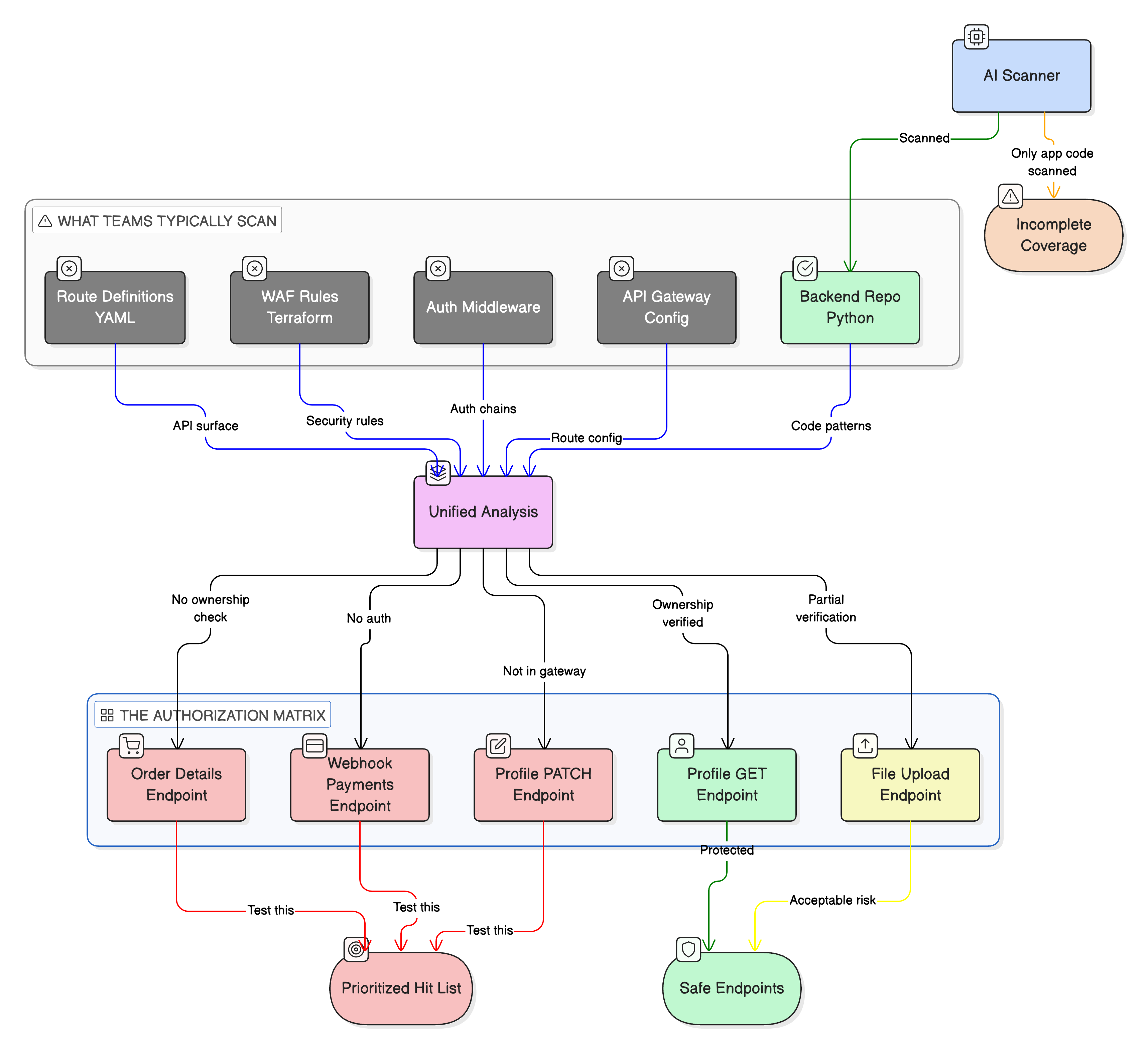
Then you organize findings into categories that actually map to your system. Not generic OWASP buckets, but patterns you can grep for in your own code:
Endpoints accepting identity parameters that don’t route through your ownership validation function. That’s a potential IDOR. You confirm it by searching the codebase for everywhere that the identity parameter flows and checking which middleware chains include the authorization check.
Webhook handlers that might not validate signatures. Your API gets callbacks from third-party providers. Does the handler verify the HMAC? Constant-time comparison? Nonce or timestamp check? You can answer all of this from the source code before sending a single request.
PATCH handlers that exist in the back-end but might not be exposed through the gateway. Routes say one thing, back-end says another. If there’s a catch-all proxy rule, the handler might still be reachable. Static analysis tells you. Dynamic testing confirms.
Mass assignment where the request body flows straight to the database without field filtering. Does your PUT handler accept audit fields, status flags, role parameters that a regular user shouldn’t touch? Read the code, trace the flow.
Here’s the shift: you only move to dynamic testing when the code confirms a gap. Not before. You’re not blind-fuzzing 200 endpoints. You’re actually testing the 15 that the code tells you are worth testing.
And when you do test, you’re not throwing generic payloads. You authenticate as User A, request User B’s data, and observe the result. You craft exact parameters, supply the right tokens and the right headers. You’re not asking, “Is this endpoint vulnerable to anything?” You’re asking, “This specific code path is missing this specific check. Can I actually reach it from the outside?”
Instead of 200 findings where half are noise, you get maybe 15 confirmed, exploitable vulnerabilities. With reproduction steps. With evidence. With severity validated against the actual production environment. With the exact code location for the fix. That’s something your engineering team can actually work with.
I recently ran this exact approach against an internal service. Static analysis mapped 46 endpoints across two repos, built the full authorization matrix, and identified 10 vulnerability categories worth investigating. Webhook handlers with no signature validation. Endpoints accepting identity params without ownership checks. Internal APIs potentially exposed through catch-all gateway rules. PATCH handlers bypassing immutability checks.
Dynamic testing then confirmed which were actually exploitable. Some were. Most weren’t, because a gateway or middleware I hadn’t accounted for was doing its job. But I knew before I tested. The static analysis gave me a prioritized hit list, not a pile of maybes.
The industry excitement about AI finding zero-days is warranted. The Ghost demo is impressive. Claude Code Security is impressive. Mythos will probably be more so. But the challenge was never just finding potential vulnerabilities. We’ve had tools generating long lists of potential issues for decades. The challenge is knowing which ones are real.
SAST alone, even AI-powered, can’t tell you that. It reads code. Code is an incomplete picture of reality. Your actual security posture depends on how the thing is deployed, how it’s configured, what sits in front of it, what happens at runtime.
This is the loop: static analysis builds the map, authorization matrix shows where the gaps are, dynamic testing tells you which gaps are actually exploitable. What you end up with is a short list of things that are actually broken, with proof.
I’m building this. I think everyone should be.
Rotimi Akinyele is the Vice President of Security at Deriv.
Follow our official LinkedIn page for company updates and upcoming events.
Join our team to work on projects like this.